Document Management Systems: SCAN (Smart Content Aggregation and Navigation)

Back in March, I began evaluating some open source Document Management Systems (DMS) to help compliment my wiki-based Personal Knowledge Manager (PKM). That’s a little bit of acronym-overload. But, in simple terms I really am looking for a way to easily store, categorize, and retrieve a number of my documents related to research and learning (PDFs, Word Docs, etc).
I quickly discovered that although my wiki can manage attaching simple documents, there was no way to easily store metadata for the documents or search within the wiki itself. As I alluded to in my original post, I narrowed down my search to 3 main DMS choices: SCAN, Alfresco, and Knowledge Tree. Of these three, SCAN (Smart Content Aggregation and Navigation) ended up being the most feature-rich and least complicated. Alfresco and Knowledge tree are both fantastic products, but they ended up being too complex for my needs. I believe this ultimately boiled down to the fact that my DMS is for one person (me) and not an entire team or company. Many features related to roles, access restrictions, and document workflow aren’t a concern to me right now.
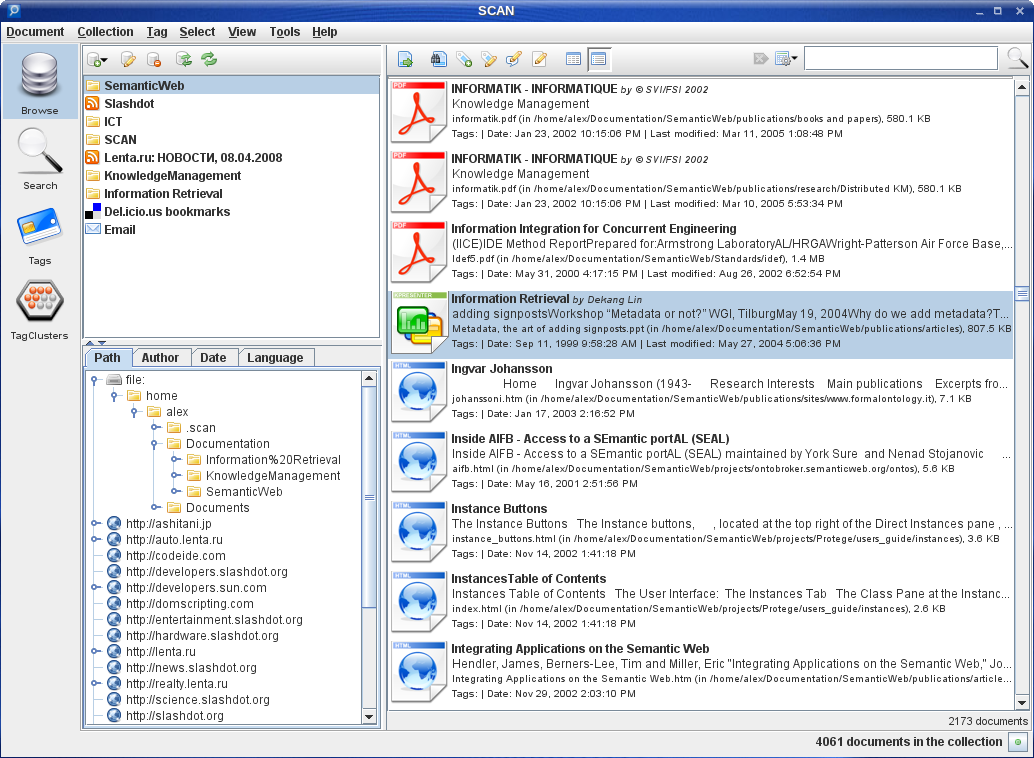
At a high-level, SCAN supports the following features:
- Java-based UI with a multitude of browsing, searching, and tagging functions (Can run on a variety of platforms – Linux, Mac, & Windows
- Support (with plugins) for PDF, Word, Excel, XML/XHTML, Plain text
- Tag cluster browsing for both Documents and Del.icio.us links
- Sophisticated tagging and text analysis
A full list of features can be found here. I received an anonymous tip the other day (well, it was actually from a guest Google chatter) that SCAN version 1.3 was just released. This release has a number of UI enhancements for browsing the document collections, adding document annotations, and better management of metadata through document properties.
For the most part, SCAN ended up being my “Killer App” for Document Management Systems. One slight drawback on my wishlist is that there is no web-interface for SCAN. Most of my time spent searching, browsing, and tagging will more than likely be on my primary desktop where SCAN is installed. Using the SCAN GUI is fine for 90% of the time, however if I am remote I would like to have access to my documents.
For the short-term I’ve simply configured my wiki to display my document repository so I can download documents as needed. What’s convenient is that I can preserve the document directory hierarchy however I like in the file system. And with SCAN, I can choose to create multiple document repositories and organize & aggregate my document collections with tags. Sure, I can only get a hierarchy (file system) list for my web view, but this is OK for now.
Long-term, I would like to experiment with adding the following features for my own needs (I am a fan of Eating My Own Dog Food or Sipping My Own Champagne):
- Add support for password-protected PDFs (if this is possible with Lucene)
- Add support for indexing and searching MindManager mindmaps. This is a *huge* must have for me given the number of mindmaps I’ve created for my own research.
- Create a basic SOAP-based service layer on top of SCAN so I can access metadata, create tag clouds, and search from a web-interface. This web-interface will more than likely be a barebones MediaWiki plugin.
This, of course, will need to be added to my ever-growing Personal Pet Project Queue.
I’d highly recommend giving SCAN a whirl, especially if you’re interested in wrangling a large number of documents. SCAN is simple, effective, & powerful. And, best of all, it’s free!
One Response
Thanks for the info. I’ve used many different DMS’s. I’ll have to take a look into SCAN.