Firefox Scrapbook Hacks – Viewing and Saving Webpages from Anywhere!
This weekend I decided to wrap up a couple cool knowledge management “hacks” and share some code on GitHub. I primarily use the Firefox Scrapbook plugin to save all web pages of interest and use it as a general “digital snippet” repository. Since I started using Scrapbook in 2006 there have been a number of online services that have come along to offer this functionality (namely Evernote, Zotero, and countless others). Some of these services make it very easy to universally access and save webpages between multiple devices. As part of my usual DIY philosophy, I’ve made an effort to stick with Scrapbook and build the missing features myself. This is in large part due to data ownership (it’s my data and I don’t want to be tied to a single service/company), plus it’s fun to tinker and make these useful “hacks”.
In Dec ’09 I shared a blog post about how to synchronize the scrapbook data between multiple computers. This was the first major step to sharing data between multiple devices, but still lacked some of the ubiquity that I desired. In a nutshell I’ve made 2 major enhancements to Scrapbook:
- An email ‘bridge’ to Scrapbook so I can email links from any device (PC, iPhone, iPad) and have them saved by Scrapbook
- A centralized web-interface to browse/search/filter my scrapbook data.
I’ll start off with the less visually-stunning hack (email bridge), but by far the craftier of two.
Hack #1 – Scrapbook Email Interface
Whenever I began synchronizing my Scrapbook data between the 2-3 computers this solved a huge problem with being able to save webpages from anywhere. Since 2009 a lot has changed, and devices like iPhone and iPad (yes, Apple fan boy to a degree) have changed the way we consume news. Recently I’ve been using apps on the iPad like Zite and Flipboard to consolidate my Twitter, Facebook, and Googler Reader feeds into a single personalized newspaper. This means that now > 50% of my reading time is spent from a device that has no visibility into my Scrapbook data. I simply wanted a way to automatically email a link (built nativily into these apps) and have it automagically saved into my Scrapbook folder. I could have simply cut corners and wrote a script to hand-edit the Scrapbook RDF Files and save the web page using something like wget or curl. But, it just wouldn’t be the same…. I want the webpage saved EXACTLY as Firefox would normally render and save it.
This poses a bit of a technical challenge, since Scrapbook runs inside Firefox and there’s no native way to interface with a plugin running inside a browser. After researching a number of approaches, I came across 2 Firefox plugins that let you build interfaces inside firefox (http, telent, etc.) that actually let you control the browser and execute Javascript. Of the 2 plugins; POW and MozRepl, I decided to go with POW (Plain Old Webserver). Both plugins are wicked cool in the sense that they’re non-traditional and very powerful. POW runs a webserver inside firefox and let’s you run your ‘server-side’ scripts as Javascript. I’ve basically written a server process that runs INSIDE the client and executes XPCOM/Javascript to control the web browser windows and invokes the Scrapbook plugin API directly.
The setup process is simple:
- Setup and install the POW and Scrapbook plugins in your browser
- Configure POW to run a desired port and create a new directory /scrapbook/
- Copy the index.sjs (server-side javascript) to this new /scrapbook/ directory
- Setup a new email box or alias (e.g. [email protected])
- Either run scrapbook2email.pl manually or run as a CRON job every couple minutes
- Simply send emails to your new Scrapbook email, run the email script, and watch your pages be saved automatically
At a high-level this is accomplished with 2 scripts:
Email Interface script (Perl)
This script uses IMAP to retrieve scrapbook email requests from a designated folder. Along with doing basic sender/recipient validation, the script is also aware of plain text/multipart messages. Once the email request is parsed, the link of the requested web page to be saved will be extracted. Given the request URL the script will then contact the POW server and pass the requested URL (e.g. http://127.0.0.1:6670/scrapbook/?url=http://yourwebpagetobesaved.com/?articleID=3q4e3332). Note that this version of the script requires that Firefox/POW be running and makes no attempt to launch for you.
For a copy of the script click here (GitHub).
Scrapbook/POW Bridge (Server-Side Javascript)
This script does the heavy lifting, and is essentially running at the other end of the POW server URL (http://127.0.0.1:6670/scrapbook/). Once the requested URL is detected the browser will spawn a new tab, automatically execute the Scrapbook Capture request, and save the webpage to a new top-level folder (e.g. Unfiled/MM-DD-YYYY). This script was tested with Scrapbook v.1.3.7.
For a copy of the script click here (GitHub).
It’s nifty now to email a link to my Scrapbook Bot and wihin a couple minutes a little notify popup shows in Firefox indicating my page was saved.
Hack #2 – Scrapbook Browser
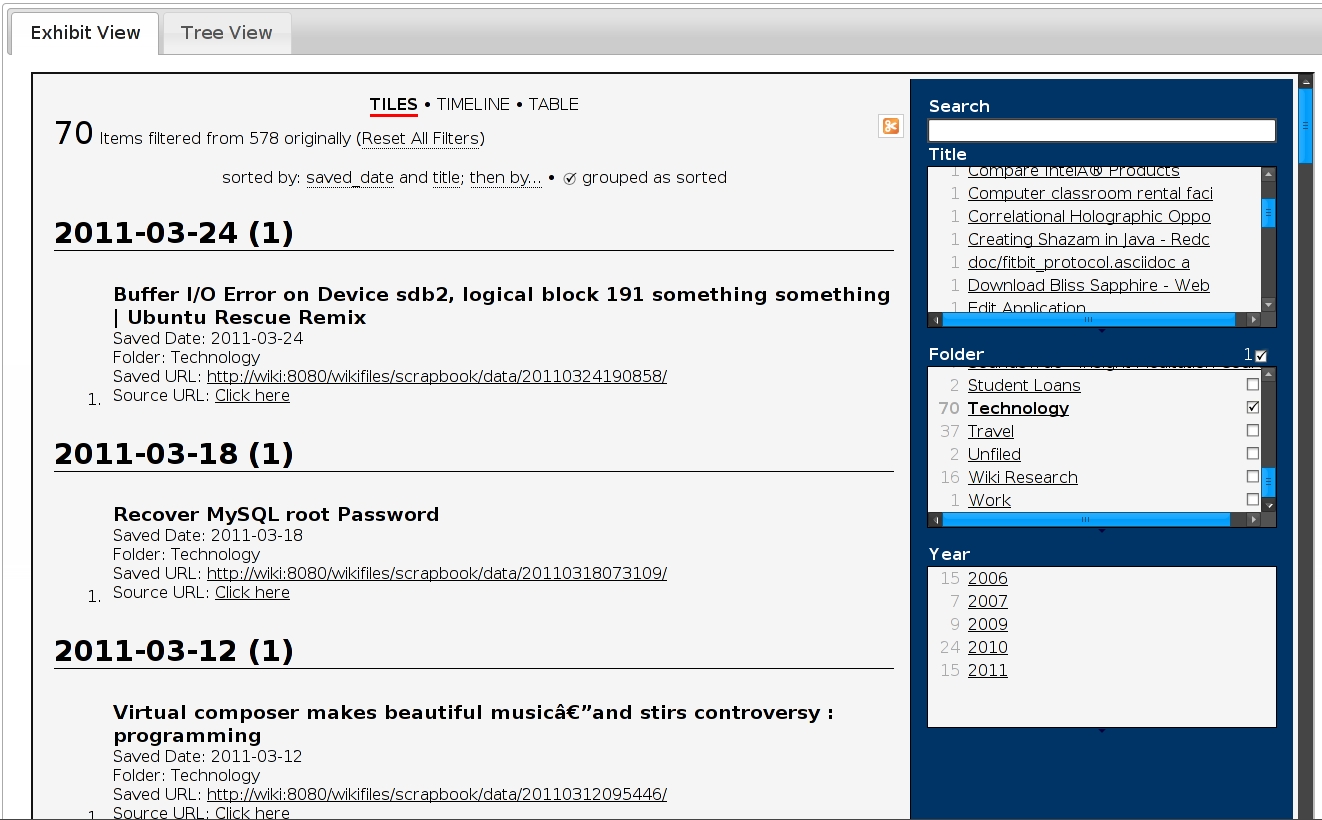
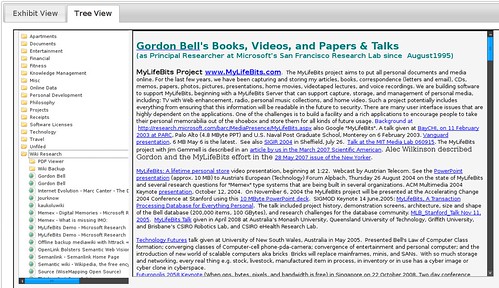
This code was actually written back in Dec ’09 after I wrote the synchronize blog post (and around the time I wrote the Document Viewer), however I haven’t shared until now. What I’ve done is write a simple Perl/JQuery web app that used Simile’s Exhibit to view Scrapbook data in a tile, table, or timeline. This interface also has a file/folder view so you can browse snippets just like you can through the native Scrapbook plugin interface within Firefox.
Here are some screenshots:
Tile View
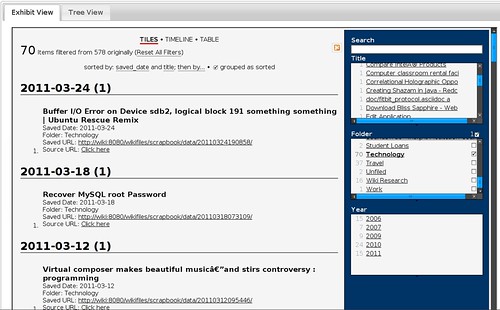
Timeline View
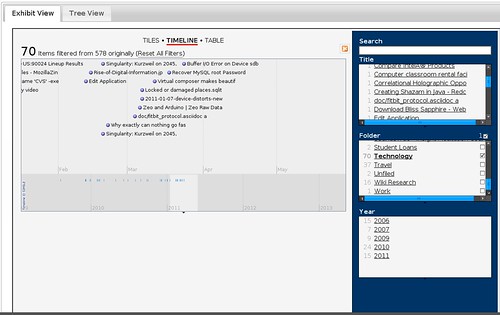
Table View
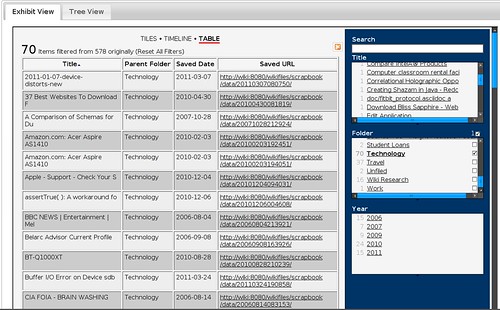
Folder View
To download the code click here (GitHub).
5 Responses
Wow. Great work! I’ve been looking for a good tool to do both things – kinda took the fun out of building it for me, but this is exactly what I needed.
Hello, can i use “Hack #2 – Scrapbook Browser” on winxp? How?
Eric, your Hack #2 in ‘folder view’ mode looks to be exactly what I’ve always desired…but it is oriented around the scrapbook extension instead of being a stand-alone web app…sigh.
It is a shame that I am no coder; merely a guy who loves the idea of using web access (privately) to store and use my treasured info from anyplace I may be.
Seems to me that it is such a normal thing now for folks to have a website and some hosted space, and that it is merely a logical next step to use it as one’s own info management portal.
But…to do this (minus some 3rd party service, etc.) would require a web-app for this purpose, neatly accessed from anyplace via browser, and for me – the ability to simply drop pre-existing TXT files into it’s folder structure for use in the app.
It would be a wish come true !
Best Wishes, and thanks for sharing your work.
Mark, you said it…. I am gonna check this hack but really i wish there was such thing as…ALL the option from “pinprest””pocket””etc” for displaying (output2html) and for sorting (tags).
I personally use it for is local so i wish i could set the path naming folder policy so that when i save in specific folder it goes were i want already sorted in “mylibrary” for example(kill two bird with one stone)
But best of all, really would be to NOT HAVE:
-data
-20121212140512
index.html
index.dat
VIDEOFILE/IMAGE/TEXT
that’s ridiculous….. one html for all page with div that fetch the specific file(img in image folder…..avi in video folder etc) would be way better that having each pertinent file saved to you pc but buried under multiple folder
Amazing work, thanks for sharing this. I’ve had a multi-gig Scrapbook going for some years then got sucked into Evernote due to much of what you mentioned here, though without the skill to execute a good approach. I’ve only gone as far as playing with Dropbox with my Scraps until I dorked something up and chickened out of leaving it that way.
I would like Evernote more if it clipped even half as nicely as Scrapbook, especially when it comes to grabbing attached files from a page. That and there is no good way of importing Scrapbook data into EN without a data massacre. I always have (in the back of my head) the worry that the extension and the Plus versions might be abandoned.
Back in the XP days, I had Scrapbook on it’s own partition just to make searching all drives easier without getting swamped in the muck of the gazillion subfolders Scrapbook creates (I know there are other ways around it…).
I’m glad to see someone coming up with clever ways to get around it’s limitations..I hope it inspires more people. That browser has me eager to browse my notes in a new, much less frustrating light.